Usage-Based Pricing Isn't Always Best
When not to make consumption your primary pricing metric.
Usage-based pricing
Usage-based pricing has been the darling of SaaS founders since Twilio, Stripe, and Snowflake emerged in the 2010s. However, effective application requires specific conditions, not indiscriminate adoption.
🪧 PSA: The terms “usage” and “consumption pricing” are used interchangeably throughout.
First, the setting
I draw on my IBM experience observing the data warehouse market disruption. Hadoop promised cost-effective solutions but underdelivered. Spark continued this trajectory, while Databricks gained momentum. Simultaneously, IaaS became reliable and trustworthy, eliminating on-premises infrastructure costs.
New data warehousing competitors emerged offering “pay only for what you used” models.

And now, a story
As a pricing analyst at Netezza (acquired by IBM for $1.7B in 2009), I witnessed competitive pressure firsthand. Netezza charged approximately $700-800k per 42U rack annually with 15% support fees. Customers prioritized speed over disk space.
Around 2014-2015, Snowflake disrupted the market.
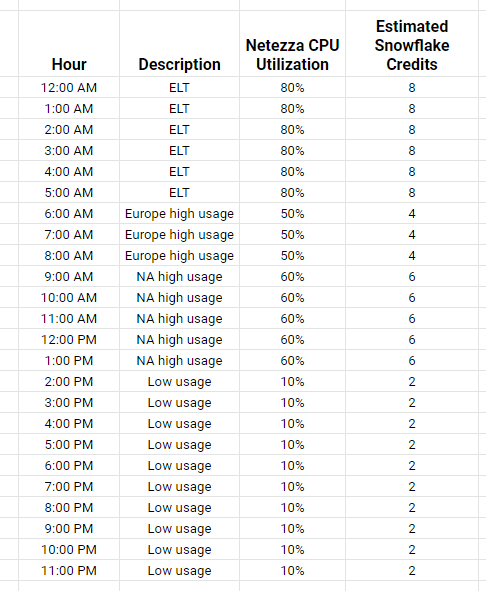
Snowflake sales teams demonstrated cost comparisons showing their pricing at 20-30% of the TCO of an equivalent Netezza system. This worked because Snowflake leveraged IaaS elasticity, allowing customers to scale dynamically rather than maintaining expensive permanent infrastructure.
The fundamental insight: many Netezza customers had extended ETL periods (6+ hours daily), paying millions to compensate for poor data engineering practices.
Snowflake ultimately dominated. IBM discontinued Netezza in favor of columnar DB2 solutions, though “Netezza Performance Server” was later resurrected.
Similar dynamics applied to Stripe and Twilio, which disrupted expensive, inflexible legacy services through IaaS-enabled consumption pricing with dramatically lower total cost of ownership.
When should you use usage-based pricing?
Many companies inappropriately force consumption pricing into their models. Success requires specific conditions:
Rule 1: Usage-based pricing saves customers money based on previous spending
Usage-based pricing makes the most sense when it allows customers to save money. This addresses the classic problems:
- Unpredictable charges
- Metric confusion
GitHub exemplifies the challenge. While Git collaboration platforms generate tremendous value, no historical budget line item exists for comparison, making cost-savings arguments impossible.
Rule 2: Use consumption as a secondary metric to capture high-value customers
Most B2B SaaS revenue concentrates among a small percentage of clients (Pareto Principle / fat tail concept). Usage-based pricing can function as a secondary tier cap, making initial adoption accessible while creating expansion revenue from the 0.1% of companies embedding the product extensively.
So now what?
Each product requires customized pricing strategies. I’d recommend:
- Early stage: Experiment through customer conversations
- Mid-to-later stage: Test different metrics and caps
- Continuous: Iterate until finding effective pricing
I welcome alternative perspectives.